文献阅读:LightGT:A Light Graph Transformer for Multimedia Recommendation
使用阅读工具: 靠岸学术
环境安装: # 配置Cuda及Cudnn,在Anaconda创建虚拟环境,安装GPU版Pytorch,并在Jupyter noterbook及Pycharm中调用【极其详细】
摘要与背景
多媒体推荐方法(Multimedia recommandation method) 旨在发现用户对 多模态信息(multi-model information) 的偏好,以增强基于 协同过滤(collaborative filtering (CF)) 的推荐系统。然而,他们很少考虑 特征提取(feature extraction) 对用户偏好建模和用户-物品交互预测的影响,因为提取的特征包含过多与推荐无关的信息。
为了从提取的特征中捕获信息性特征,使用了Transformer模型来建立同一用户历史交互物品之间的关联。考虑到其在有效性和效率方面的挑战,提出了一种基于Transformer的推荐模型,称为 Light Graph Transformer(LightGT)
引言
为了从物品的内容信息中预测用户偏好,先前的研究大多遵循类似的流程:多模态特征提取、用户偏好建模以及用户-物品相似度测量。尽管这些模型引入了一些先进的技术来增强推荐效果,例如深度神经网络和图卷积网络(GCNs),但它们很少探索提取的特征,而这些特征是用户偏好建模和后续交互预测的基础。
通过探究现有模型,作者认为提取的特征包含大量与推荐任务无关的信息,因此未能充分地从物品内容中建模用户偏好.
以预训练的ResNet提取的视觉特征为例,判别性信号往往被强调以区分来自不同类别的图像。然而,这种信号可能对用户偏好建模起着不重要的作用。例如,鞋带的特征可以帮助分类器区分运动鞋和正装鞋,但它们在用户-物品交互预测中的重要性将会下降。
为了克服这个问题,从现成的特征中提取信息线索以建模用户偏好至关重要。现有的研究利用注意力机制或深度学习方法,通过显式或隐式地重构用户-物品历史交互来提取信息信号。然而,它们忽略了在特征提取过程中,同一用户观察到的物品之间的相关性,而这种相关性揭示了用户对内容信息的兴趣。这与“相似的物品更易于推荐给同一用户”的假设相一致。也就是说,某些在物品中共同出现的特征反映了用户在内容信息方面的品味。因此,建立同一用户观察到的物品之间的相关性能够发现影响用户决策的信息性特征。
挑战
使用了Transformer来建模同一用户观察到的物品之间的相关性,但直接继承Transformer模型在工作中存在挑战:
- 如何有效地测量基于现成特征的物品之间的亲和力:物品的提取特征作为Transformer的输入,依赖于预训练的提取器,因此一些无关的信息可能会损害物品对之间的相关性建模
- 面对过载和多样化的输入,如何高效地执行基于Transformer的模型:推荐系统中输入的token是大量物品的指数组合(比如M个用户,L个物品,最坏情况是每个用户都与L个物品发生交互,计算注意力的复杂度就为 $O(M*L^2))$
主要改进
- 模态特定的嵌入(modal-specific embedding)
- 逐层位置编码器(layer-wise position encoder)
- 轻量自注意力块(light self-attention block)
相关知识概述
多媒体推荐 Multimedia Recommendation
什么是推荐模型?
推荐模型的目标是对每个用户未观察到的物品的兴趣进行评分,并按照降序排列这些分数以进行推荐
具体做法:
$$
\begin{align*}
给定一个包含N个用户的集合\mathcal{U}和一个包含M个物品的集合\mathcal{I} \
在观察到的用户-物品交互数据集合 \mathcal{O}={(u,i)|u \in \mathcal{U},i \in \mathcal{I}}的监督下 \
\end{align*}
$$
基于协同过滤的推荐系统被广泛用于学习用户和物品的嵌入表示,并评估他们的相似度
形式上,将用户的嵌入表示和物品的嵌入表示输入到评分函数f()中
$$
\begin{align*}
s_{u,i}=f(e_{u},e_{i}) \
其中: \
e_{u}\in R^d,e_{i} \in R^d 分别表示用户u和物品i的嵌入,d是向量的维度\
s_{u,i}是一个分数,反映了用户u基于其历史行为对物品i感兴趣的可能性
\end{align*}
$$
多模态
为了增强基于协同过滤(CF)的推荐模型,一些辅助信息,如产品图片和视频关键帧,被用来建模用户对物品内容的偏好。不失一般性,我们考虑包含视觉、听觉和文本模态的多媒体信号,并学习用户在每个模态中的偏好
$$
\begin{align*}
我们将m \in \mathcal{M}={v,a,t}定义为模态指示符 \
其中v,a,t分别代表视觉、听觉和文本模态
\end{align*}
$$
基于多模态信息,我们的目标是学习模态特定的用户偏好,并根据提出的模型对用户-物品对的相似度进行建模
$$
\begin{align}
s_{u,i}^m=g(f_{u}^m,f_{i}^m) \
其中s_{u,i}^m是用户和物品之间基于内容的相似度 \
f_{u}^m \in R^d和f_{i}^m \in R^d分别表示用户u的偏好和项目i在模态m上的表示
\end{align}
$$
原始Transformer - Vanilla Transformer
回顾最初的Transformer,我们大致将操作分组为具有相同架构的多个块,每个块由自注意力模块和逐位置的前馈神经网络(FFN)组成。为了堆叠这些块,在连续的块之间插入残差连接和层归一化(Layer Normalization),以促进更深层Transformer模型的优化。
自注意力模块
通过将一系列 tokens(例如,单词、帧和项目)输入到 Transformer 模型中,自注意力模块旨在估计 tokens 之间的相似性,然后生成输出矩阵

多头自注意力模块
可以将token映射到不同的空间,以便从不同方面综合衡量相似性

前馈神经网络FFN

残差连接

研究方法
LightGT模型

Figure 1: An illustration of our proposed model.
使用前面提到的改进方法扩展了原始的Transformer模型:
模态特定的嵌入 - Modal-specific Embedding
作用:用于编码LightGT模型在不同模态下的输入
将用户及其交互过的物品作为模型的token;将token嵌入每种模态中,以便于学习模态特定的用户偏好
以图中用户u及其交互过的物品 $i_{1},i_{2},i_{3},i_{4}$ 为例,它们可以表示为:
$$
\begin{align}
F_{u}^m=[f_{u}^m,f_{i_{1}}^m,f_{i_{2}}^m,f_{i_{3}}^m,f_{i_{4}}^m] \
其中f_{ik}^m(k=1,2,3,4)表示模态m中物品i_{1},i_{2},i_{3},i_{4}的特征 \
它们通过预训练的特征提取器从内容信息中捕获,并压缩为d维向量 \
f_{u}^m表示用户u在模态m中的可训练表示 \
收集这些向量后,为用户偏好建模生成模态特定的标记表示为F_{u}^m
\end{align}
$$
逐层位置编码 - Layer-wise Position Encoder
作用:它通过为token添加其在历史交互中扮演的角色信息来增强token的表征
通常,位置信息在Transformer模型中起着至关重要的作用,它提供先验知识以增强注意力测量。与序列输入(例如,句子中的单词和视频中的帧)不同,我们获得的token不知道其在序列中的位置。因此,作者利用**用户-物品图(user-item graph)的结构信息来编码token的位置,这反映了它们在历史用户-物品交互中的关系。
为此,作者定义了用户和物品的id嵌入,然后将历史记录中的用户-物品交互重组为一个二分图
什么是二分图?
图论中一种特殊结构,顶点集可以被划分为两个互不相交的子集A和B,使得图中的每一条边都连接来自不同子集的顶点,也就是说,二分图不存在任何一条边连接同一个子集内部的顶点
用户-物品交互二分图为:
$$
\begin{align}
\mathcal{G}={E,A} \
其中: \
E \in R^{(N+M)\times d}是用户和项目节点的可训练嵌入矩阵 \
A \in [0,1]^{(N+M)\times(N+M)},即形状为(N+M)\times(N+M)的01邻接矩阵,用作二分图的边 \
A_{ui}=1表示用户u和项目i之间存在观察到的交互,否则A_{ui}=0
\end{align}
$$
根据交互图的构建,结构信息可以反映推荐场景中节点间的关联性。具有更多共同邻居的节点往往具有更相似的表示。
因此,可以利用从图中学习到的结构信息的表示来编码相应节点的位置
为了编码位置信息,我们采用在二分图上的GCN模型来进行结构信息建模。通过迭代地执行堆叠的图卷积层,我们可以将来自多跳邻居的消息传递到中心节点,从而使用邻居的嵌入来表示它们的结构信息
以第 $l$ 层为例,我们通过聚合节点的邻居嵌入来建模节点的邻居信息,使用朴素对称归一化矩阵 $A_{naive} = D^{-1}AD^{-1}=\frac{A_{ij}}{d_{i}d_{j}}$
形式上为:
$$
\begin{align}
e_{u}^{(l)} =\sum_{i \in \mathcal{N}{u}} \frac{1}{\sqrt{ |\mathcal{N}{i}| }\sqrt{ |\mathcal{N}{u}| }}e{i}^{(l-1)}\
e_{i}^{(l)}=\sum_{u \in \mathcal{N}{i}} \frac{1}{\sqrt{ |\mathcal{N}{i}| }\sqrt{ |\mathcal{N}{u}| }}e{u}^{(l-1)} \
\mathcal{N_{u}}:用户u的邻居物品\
|\mathcal{N_{u}}|:用户u的度 \
\mathcal{N_{i}}:物品i的邻居用户 \
|\mathcal{N}{i}|:物品i的度 \
e{u}^{(l)}和e_{i}^{(l)}是从用户u和项目i的l跳邻居学习到的结构信息
\end{align}
$$
实现逐层位置编码器,它吸收结构信息并为不同的自注意力块生成位置编码,形式上如下:
加权平均,融合多层图卷积层学到的结构信息
$E^{(l)}$ 表示从第 $l$ 个图卷积层学到的结构信息的表示; $\hat{E}^{(l)}$ 表示第 $l$ 个自注意力块的位置编码
此编码器的动机是,当我们堆叠自注意力块时,我们需要更充分的结构信息来帮助自注意力评分
训练阶段初期,由于从现成的提取器中学到的信号不相关,导致tokens表征的置信度较低;为了减轻它们对结构信息建模的负面反馈,在位置编码器中引入了停止梯度操作,形式上为

stopgrad()表示停止梯度,用于切断从自注意力模块到用户和物品嵌入的反向传播
过程可以总结成: 用户物品历史交互重组成二分图->多层GCN进行信息聚合->加权平均融合多层结构信息得到第l个自注意力块的位置编码->让Transformer感知二分图结构位置关联
轻量级自注意力块 - Light Self-aention Block
该模块可以堆叠起来,以对token之间的相关性进行建模从而进行用户偏好建模
Figure 2: An illustration of the 𝑙-th light self-attention block.
由于推荐系统中数据过载和稀疏交互,难以有效且准确地优化标准Transformer; 通过简化原始Transformer中繁重累赘的组件,作者设计了一个轻量级自注意力模块
首先将tokens的位置编码 $\hat{E}_{u}^{(l)}$ 嵌入到其表示中,如figure 2表示,第 $l$ 个块中,将token的 位置增强表示 形式化为
$$
\begin{align}
H_{u}^{(l)}=sigmoid(W_{m}\hat{E}{u}^{(l)}+b{m})⊕F_{u}^{(l-1)} \
⊕表示逐元素加法运算 \
F_{u}^{(l-1)}表示从前一个块学习到的tokens的表示 \
H_{u}^{(l)}是第l层的富含位置信息的token表示
\end{align}
$$
疑问?
示意图中的处理线性变换的激活函数使用relu,但是实际公式和代码中都是sigmoid
应该是作者笔误了吧(雾
得到了富含位置信息的token表示之后,我们可以获得用于相似性度量的查询向量(Query)和键向量(Key)
$$
Q=W^QH_{u}^{(l)}(,K=W^KH_{u}^{(l)}
$$
作者移除了初始Transformer中的FFN和残差连接,更重要的是,作者发现 单头注意力模块可以达到与多头注意力模块相当的性能 ,因此,进行带缩放因子的自注意力运算
$$
\begin{align}
F_{u}^* = softmax\left( \frac{QK^T}{\sqrt{ d }} \right)W^VF_{u}^{(l-1)} \
F_{u}^*是由聚合上下文信息增强的tokens表示.W^V \in R^{d\times d}表示获取值向量的参数
\end{align}
$$
这里为什么使用没有位置编码的 $F_u^{(l-1)}$ 呢?
因为要专注于用户对内容信息的偏好,避免来自id嵌入的影响
使用层归一化得到第 $l$ 个自注意力块生成的tokens表示:
$F_{u}^{(l)}=LayerNorm(F_{u}^*)$
利用自注意力机制,我们对用户-物品和物品-物品对的关系进行建模.
其中用户-物品亲和度有助于强调用户偏好的物品特征,而物品-物品相关性则突出了影响用户决策的共现信息
用户偏好建模 - User preference Modeling
堆叠L个自注意力块,我们获得输入物品和用户的tokens的增强表示
对于用户,一些信息线索在不同的块中被捕获,并与其表示进行聚合
使用一个 全连接网络(FCN) 对用户对物品内容的偏好进行建模
$$
\begin{align}
\hat{f}{u}=leaky_{relu}(W’{m}f_{u}^{(L)}+b_{m}’) \
f_{u}^{(L)} \in F_{u}^{(L)},表示用户u在第L个轻量级自注意力模块后的表示 \
W_{m}’和b_{m}’分别是投影矩阵和偏置向量
\end{align}
$$
最终我们获得了增强的用户偏好表示 $\hat{f}_{u}$
模型预测 - Model Prediction
基于图卷积网络实现基于协同过滤的用户和物品嵌入.通过结合从L层学习到的结构信息(又称协同信号),我们可以将高阶交互信息注入到嵌入中
$$
e_{u}=\sum_{l=0}^{L}e_{u}^{(l)},e_{i}=\sum_{l=0}^{L}e_{i}^{(l)}
$$
然后,可以根据用户和项目基于协同过滤的表征来衡量它们之间的相似性
$s_{u,i}=e_{u}e_{i}^T$
其中 $s_{u,i}$ 是我们期望的分数,用于估计用户u根据历史行为偏好物品i的可能性
对于基于内容的分数,我们从现成的特征中获得项目特征,并计算用户和目标项目在模态𝑚上的相似度
$s_{u,i}^m=\hat{f}{u}^m(f{i}^m)^T$
其中, $s_{u,i}^m$ 表示用户u对物品i的偏好程度
利用获得的协同过滤和基于内容的评分,我们可以将它们结合起来预测用户-物品交互,形式上为:
$s_{u,i}^=\lambda s_{u,i}+(1-\lambda)\sum_{m \in \mathcal{M}}s_{u,i}^m$
其中, $\lambda$ 是一个超参数,用于平衡最终交互评分 $s_{u,i}^$ 中两种类型的信息
优化
优化提出模型的参数,应用贝叶斯个性化排序(BPR),这是一种著名的成对(pairwise)排序优化算法,并重构用户和项目之间的历史交互
构造一个三元组,包含一个用户,该用户观察到的一个物品,该用户未观察到的一个物品
$$
\begin{align}
\mathcal{R}={(u,i,i’)|(u,i)\in \mathcal{O},(u,i’)\notin \mathcal{O}} \
\mathcal{O}:观察到的用户-物品交互数据集合
\end{align}
$$
其中 $\mathcal{R}$ 是一个用于训练的三元组集合
根据用户相较于未观察到的物品,更偏爱观察到的物品的假设,BPR的目标函数表述为:
$\mathcal{L}=\sum_{(u,i,i’) \in \mathcal{R}}-\ln{\varphi(s_{u,i}^-s_{u,i’}^)}+\eta||\Theta||_{2}^2$
其中, $\varphi(\cdot{}),\eta和\Theta$ 分别表示sigmoid函数,正则化权重和文中提出的模型的可训练参数
$||\Theta||_{2}^2$ 表示对 $\Theta$ 先取L2范数再平方
实验
- 研究问题1(RQ1):相比于目前最好的捆绑推荐模型,我们提出的模型表现如何?
- 研究问题2(RQ2):LightGT中的设计(即逐层位置编码器和轻量自注意力块)如何影响我们模型的性能?
- 研究问题3(RQ3):自注意力模块中各组成部分(即多头注意力、FFN 和残差连接)的有效性和效率如何?
- 研究问题4(RQ4):LightGT能否学习到用户偏好的更优表示?
实验设置
数据集
在 Movielens,Tiktok和Kwai这三个数据集上进行了广泛的实验
数据集的介绍:
- Movielens:Movielens dataset1是为了推荐系统研究而设计的。在多媒体推荐方面,MMGCN的作者收集了视频的预告片,标题和文本描述。利用预训练模型,分别从帧、音轨和描述中提取视觉、听觉和文本特征。
- Tiktok 此数据集中的项目包含多媒体特征,涉及视觉、听觉和文本模态。根据 Tiktok2 的发布者,这些特征是由一些在非推荐数据集上预训练的深度学习模型提取的。
- Kwai:与上述两个数据集类似,Kwai数据集中的项目由特征提取器获得的多模态特征组成。这些提取器也是为不同模态的识别任务而设计的,并使用与推荐任务无关的数据集进行训练。
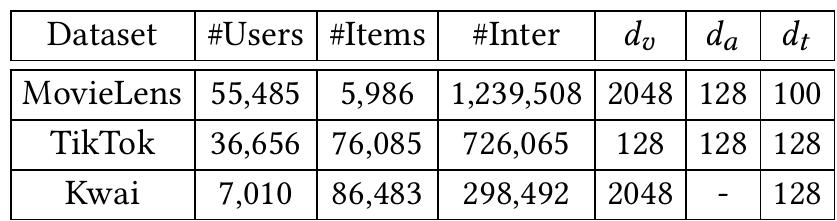
$d_{v},d_{a},d_{t}$ 分别表示视觉、声学和文本模态特征数据的维度
评估协议
对于每个数据集,按照8:1:1的比例,将每个用户的交互记录随机分割成训练集、验证集和测试集
评估指标
recall@K(R@K)召回率
在所有的正确答案中,模型推荐的前K个结果(Top-K)里包含了多少,关注的是模型的覆盖能力和避免遗漏的能力
计算公式: $R@K=(Top-K中相关的物品数)/(所有相关的物品总数)$
归一化折损累积增益(NDCG@K,N@K)
评估前K个推荐结果的质量,不仅看有多少是相关的,还要看它们排列的顺序好不好
它认为:相关的物品应该排在前面,越相关的物品,价值越高(用户更可能看到前面的结果)
最终分数被归一化到[0,1]之间
$$
NDCG@K=\frac{DCG@K}{NDCG@K}
$$
折损累积增益DCG@K
$$
DCG@K=\sum_{i=1}^k \frac{rel_{i}}{log_{2}(i+1)}
$$
其中 $rel_{i}$ 指第i个结果的真实相关性分数
理想折损累积增益IDCG@K
$$
IDCG@K=\sum_{i=1}^{|REL|} \frac{rel_{i}}{\log_{2}(i+1)}
$$
其中 $|REL|$ 表示对真实相关性分数排序后,相关结果(分数非0)的个数,最大值为k
基线模型
作者将提出的模型与最先进的基线模型进行比较,包括基于协同过滤的推荐模型(即 GraphSAGE、NGCF、GAT 和 LightGCN)和多媒体推荐模型(即 VBPR、MMGCN、GRCN 和 LATTICE)
参数设置
我们使用 Pytorch 和 torch-geometric 包 来实现我们提出的模型。特别地,我们使用 Xavier 算法 初始化模型参数,并使用 Adam 优化器 对其进行优化。对于学习率和正则化权重,我们分别在 {0.0001, 0.001, 0.01, 0.1, 1} 和 {0.00001, 0.0001, 0.001, 0.01, 0.1} 中进行网格搜索
当验证数据上的 recall@10 在连续 20 个 epoch 内没有增加时,我们停止训练,并在测试数据集上报告结果
性能比较(RQ1)

在三个数据集上,我们提出的 LightGT 大幅度优于所有基线模型。特别地,LightGT 在三个数据集上分别将最强的基线模型的 Recall 指标提高了 5.16%、22.77% 和 8.77%。这些改进验证了我们提出的模型的有效性。
在大多数情况下,LightGT 和最强的基线模型 LATTICE 的表现优于其他基线模型。这表明显式地对物品之间相关性进行建模有助于预测用户-物品交互
消融研究(RQ2)
为了测试逐层位置编码器,作者将LightGT与几个变体模型进行了比较:
- w/o PE:移除位置编码器,并且仅在内容特征上进行轻量级的自注意力模块
- w/o SG:移除了逐层位置编码器中停止梯度操作
- w/o LW:移除了逐层操作,通过所有图卷积层(LGC)学习到的结构信息的表征的平均值来计算每个块中的位置编码
LightGT始终比三个变体模型表现出更优越的性能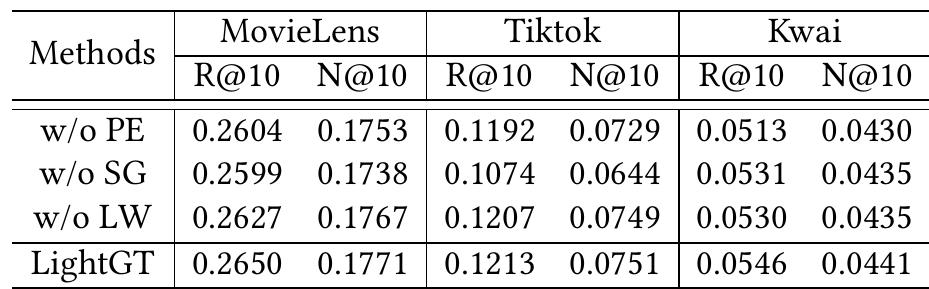
轻量自注意力块的影响
作者测试了 ${1,2,3,4}$ 范围内的层数(即块数),作为比较,作者在相同的设置下进行了LightGCN实验

(绿色:LightGT,黄色:LightGCN)
当层数大于2的时候,LightGT在三个不同的数据集上明显优于LightGCN;通过增加层数,LightGT所取得的改进比LightGCN更为显著
结论:
- 模型中更深层的GCN能够建模更全面的结构信息,并将其注入到tokens的表示中;进一步增强自注意力评分
- 堆叠的轻量级自注意力块能够从现成的特征中提取有效特征。这再次验证了提出的模型中设计的有效性和合理性
深入分析(RQ3)
多头自注意力机制的影响
为了研究基于Transformer的推荐模型中的多头自注意力机制,作者将具有2个头和4个头的自注意力模块与LightGT在三个数据集上进行了比较
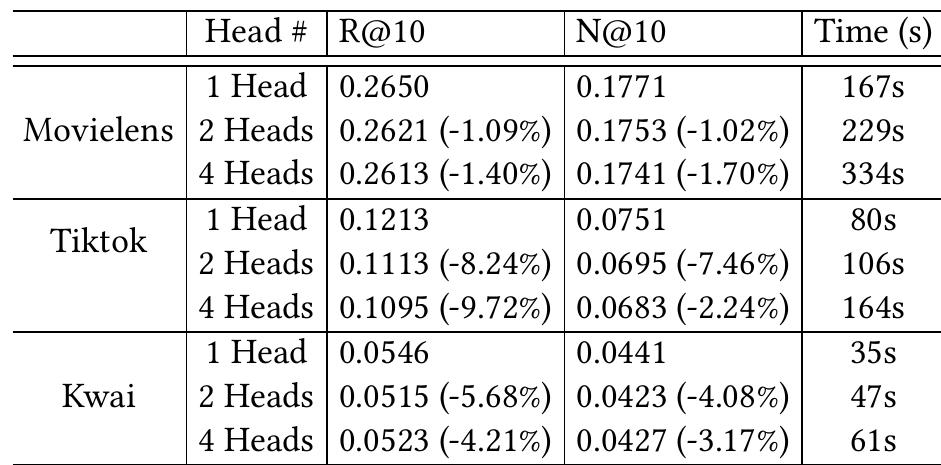
(Time(s)表示每个epoch的秒数,Head # 表示自注意力模块中的头数)
观察到LightGT始终获得在所有数据集上最好的性能。
具体而言,recall@10和NDCG@10的值随着头部数量的增加而降低,而时间成本急剧上升。
它表明多头自注意力机制在计算机视觉和自然语言处理任务中是有帮助的,但会损害推荐系统的性能。
原因可能是,在一个方面对tokens的相关性进行建模就足够了。
前馈网络FFN的影响
在轻量级自注意力模块中实现FFN,以测试其在推荐系统中的必要性
在三个数据集上进行实验,并记录关于R@10和N@10的结果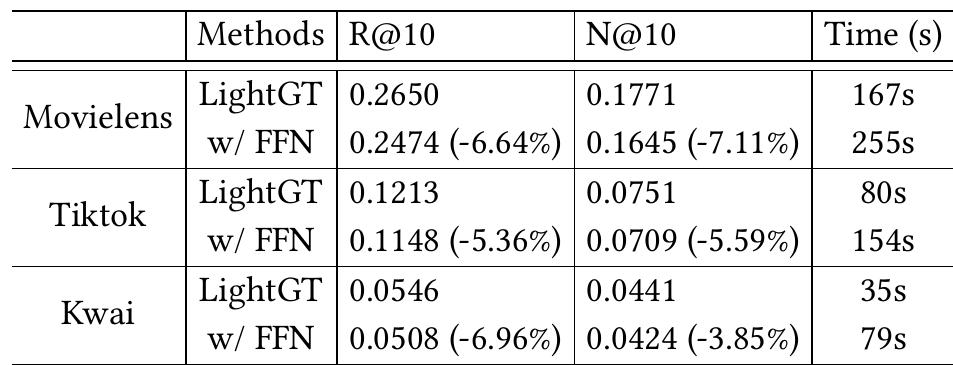
在轻量级自注意力模块中实现FFN会导致性能大幅下降
作者将其归因于过拟合,因为FFN引入了一些需要学习的参数
与计算机视觉和自然语言处理领域的任务不同,在推荐应用中充分建模语义信息可能是是不必要的
残差连接的影响
在两个连续的自注意力块之间配备残差连接(即图中的w/RC)
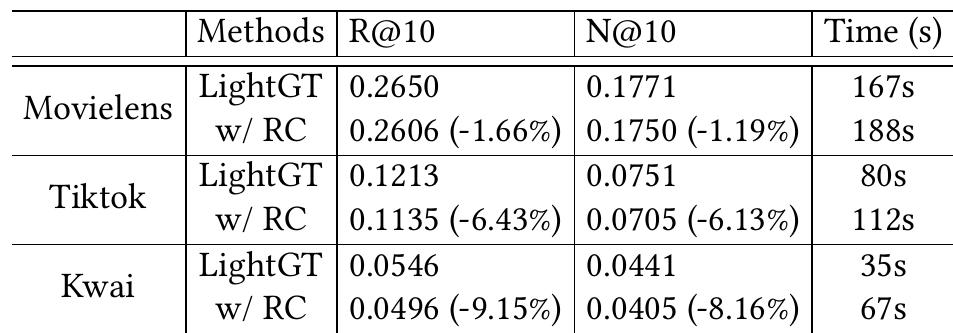
即使没有残差连接,LightGT在三个数据集上的表现也优于基线模型;并且与基线模型相比,LightGT在每个epoch花费的时间明显更少,这归功于移除了残差连接
可视化(RQ4)
从该模型中获得的表征是否能更好地衡量用户对项目内容信息的偏好
从Tiktok数据集中随机选择了6位用户,在收集了一些它们训练过程中从未交互过的物品后,我们进行了t-SNE算法以在二维空间中绘制它们的表征,并可视化从MMGCN和LightGT模型中学习到的项目和用户表征

与MMGCN模型相比,使用LightGT模型时,相同颜色的星星(用户)和点(相关物品)嵌入得更近,图中可辩别的聚类表明,LightGT模型有效地模拟了用户偏好
结论
提出了用于多媒体推荐,新的基于Transformer的模型LightGT。
设计了模态特定嵌入和逐层位置编码器,以实现有效的特征提取,并设计了轻量级自注意力块,以实现高效的自注意力评分
通过对同一用户观察到的物品之间的相关性进行建模,在用户物品交互预测中实现了对项目内容的用户偏好
复现
数据集:不要直接去README.md中给的链接下.csv文件
按照README.md中给的环境配置(==!!!注意:不要按他的环境来;这里我使用pip安装pytorch1.7.0cu101+cuda10.1,会出现很多莫名其妙的错误;用conda安装更是torch都用不了;pip安装的torch版本改成pytorch1.13.0后才解决了大部分报错;一些奇怪的错误,比如索引越界,建议多问问AI(博主也不知道为什么这么多奇奇怪怪的错误==)
1 | The code has been tested running under Python 3.8.15. The required packages are as follows: |
1 | # ps:错误的示范,不要用conda装pytorch |
出现问题:

换成pip安装就解决了
1 | pip install torch==1.7.0+cu101 torchvision==0.8.0 torchaudio==0.7.0 -f https://download.pytorch.org/whl/torch_stable.html --no-cache-dir |
1 | # 需要把parse.py中多进程数num_workers置为0,不然张量在多进程环境下序列化时会出现问题 |
遇到的问题:计算loss时不知道为什么索引越界
运行中各种报错:

解决办法:
pytorch换成1.13.0
把一些矩阵相关的方法进行维度统一
修正非法索引
(仙术AI)
复现结果:






